
ما هي هياكل البيانات (Data Structure)؟
يمكن تعريف هياكل البيانات (Data Structure) على انها الشكل او الطريقة التي تتيح لنا ترتيب وتخزين البيانات في الكمبيوتر وتهيئتها لإستخدامها بشكل سليم وبكفاءة عند التعامل معها والتعديل عليها . أي انها طريقة يتم من خلالها تنظيم البيانات وتخزينها داخل جهاز الحاسوب بالشكل التي يمكننا من إستخدامها بكفاءة عالية.
و يمكن تخزين البيانات على الأشكال التالية :
أ.بيانات أساسية من عدة أنواع (int, float,boolean char and string)
ب.بيانات مركبة (and objects List,Tuple,set , Dictionary)
والتي تظهر معنا في الشكل المجاور: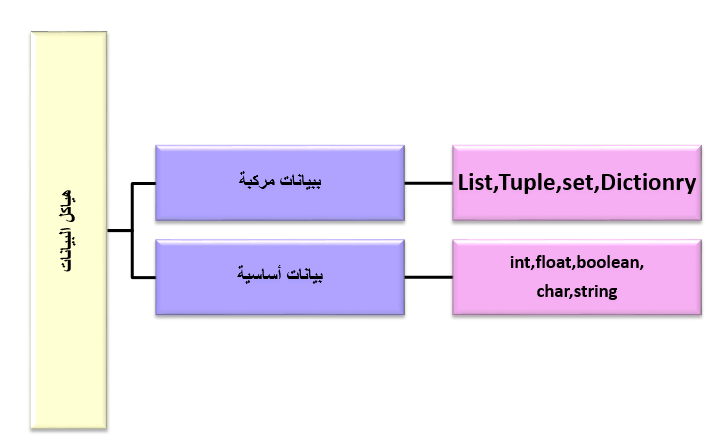
البيانات المُُركََّبة في لغة البرمجة بايثون:
البيانات المُُركََّبة هي أحد أنواع البيانات التي قد تحتوي على أكثر من قيمة، وتكون مُُرتََّبة بطريقة تُُسهل التعامل معها. حيث يتم تخزين هذه البيانات في جهاز الحاسوب على شكل منسق ومنظم يساعد المبرمج في تنفيذ العمليات المعقدة بشكل عالي الكفاءة.
وهناك أكثر من نوع من هذه البيانات المركبة ممكن التعامل معها في لغة البرمجة بايثون والتي تظهر من خلال الشكل التالي: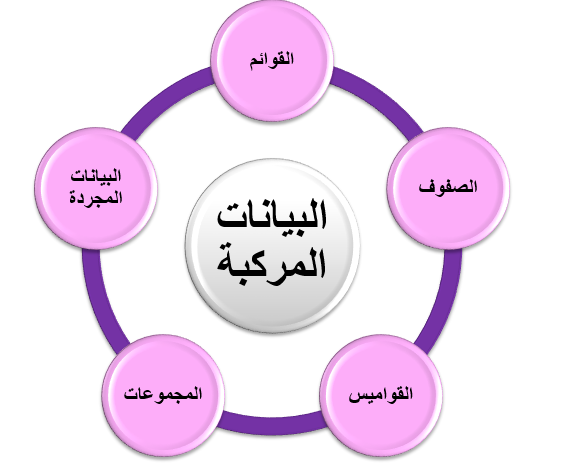
وكل نوع من هذه البيانات يمتلك خصائص تناسب مهمة معينة ومحددة. وسوف نتعرف على هذه الانواع من البيانات المركبة الشائعة في لغة البرمجة بايثون بالتفصيل .
1.القوائم (Lists)
سبق وتعرفنا على مصطلح (القائمة) وعرفناه على انه مجموعة من القيم التي يتم تخزينها مع بعضها البعض وعادة يكون هناك رابط يربط هذه القيم فيما بينها.
مثال:
- قائمة أسماء الشوارع في مدينة العقبة
- قائمة أسعار البضائع التي إشتراها العميل من تاجر معين
ويمكن للقائمة أن تحتوي على عناصر من أنواع مختلفة من البيانات (أسماء،أرقام، تواريخ) مثل: قائمة أسماء الصف الثاني عشر شعبة أ التي تحتوي على اسم الطالب رباعي، الرقم الوطني،تاريخ الميلاد .
ويمكن من خلال لغة البرمجة بايثون تعريف القائمة باستخدام الأقواس المربعة بحيث يفصل يتم الفصل بين عناصر القائمة بفواصل كما في الشكل التالي:
مثال: لتعريف قائمة تحتوي على أرقام تحمل الإسم (L) نكتب:
L = [2, 4, 6, 8]
ويوضح الشكل التالي ،مثالا يظهر لنا كيفية تعريف قائمة في لغة بايثون ومن ثم التعديل عليها من خلال أضافة عناصر ،حذف عناصر وأخيرا طباعة محتويات القائمة:
حيث تم تعريف قائمة باسم my_listثم تم اجراء العمليات التالية:
تم تخزين العناصر التالية في القائمة (1,2,3).
تم إضافة العنصر (4) الى نهاية القائمة من خلال الأمر my_list.append والذي يعمل على إضافة عنصر واحد فقط.
تم إضافة العنصر (99) بحيث يكون موقعه مكان العنصر الذي لديه رقم الفهرس هو (1) وهنا يكون مكان الرقم 2
تم اضافة العناصر (5,6,7) الى نهاية القائمة من خلال الأمر my_list.extend والذي يعمل على إضافة أكثر من عنصر .
تم حذف العنصر الذي يحمل الترتيب رقم (2) كفهرس
تم حذف العنصر الذي يحمل الترتيب رقم (6) كفهرس
تم حذف العنصر الذي يحمل القيمة (99) من القائمة
وبعد تنفيذ البرنماج من خلال محرر بايثون سوف تظهر لنا النتيجة التالية:
2.الصفوف (Tuples)
تعتبر الصفوف أحد أشكال هياكل البيانات المركبة التي يتم استخدامها لغايات تخزين البيانات مثل القوائم (Lists).
إلا انها تختلف عن القوائم بالنقاط التالية:
1.بثباتها وعدم قابليتها للتغيير،مما يعني لا يمكن تغيير العناصر الموجودة داخل الصف بعد إنشائه سواء بالإضافة أو الحذف.
2.يتم تعريف الصف(Tuple) من خلال اسم الصف ومن ثم الأقواس الدائرية التي يتم وضع العناصر فيها بحيث تفصل الفاصلة بين كل عنصر والذي يليه.
3.تحتاج الصفوف الى حجز حجم ذاكرة أقل مما تحتاجه القائم بسبب ثبات عناصرها.
والشكل التالي:
يوضح الصيغة العامة لتعريف الصف (Tuple) في لغة بايثون (Python)
حيث يمثل :
- Tuple_name :اسم الصف
- الأقواس الدائرية(): تُستخدَم في حصر عناصر الصف
- الفاصلة: للفصل بين العنصر والذي يليه.
مثال:
لنقم بتعريف صف يحمل الاسم (Tuple) ويحتوي على العناصر (5,10,15,20) ثم يعمل على طباعة هذه العناصر:
الحل:
بعد فتح (IDLE) الخاص بلغة البرمجة بايثون،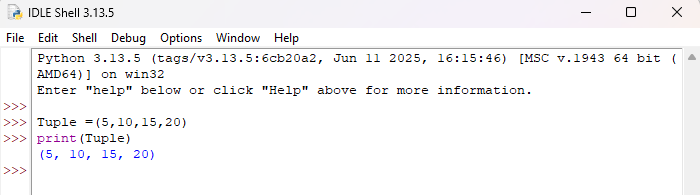
وكتابة الامر التي تمثل تعريف الصف،
ومن ثم كتابة الأمر الذي يمثل طباعة محتويات الصف،تظهر لنا النتيجة كما في الشكل التالي:
مثال(2)
والآن لنقم بتنفيذ الاوامر التالية من خلال مفسر بايثون ولنرى النتيجة:
تعريف ال (Tuple) بعنصر واحد. #
Tuple_elements = (5,)
طباعة عناصر # tuple
print(Tuple_elements)
سوف تظهر لنا النتائج التالية:

وعند حذف الفاصلة من داخل محتويات الصف،
سوف تظهر لنا النتيجة التالية:
3.القواميس (Dictionaries)
الصيغة العامة لتعريف القاموس (Dictionary)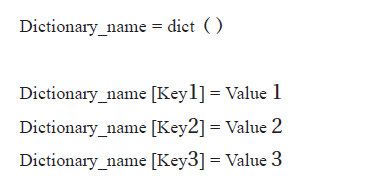 حيث يمثل :
حيث يمثل :
Dictionary_name : اسم القاموس الذي نرغب في إنشائه.
dict() : كلمة محجوزة تُُستخدََم في تعريف قاموس فارغ في لغة البرمجة بايثون، وتوضََع أقواس دائرية بعدها.
Key1: الكلمة المفتاحية الأولى في القاموس، وهي المفتاح الذي يمكن عن طريقه الوصول إلى
القيمة.
Value1: القيمة المُُربِتِطة بالمفتاح الأوََّل في القاموس.
Key2: الكلمة المفتاحية الثانية في القاموس، وهي المفتاح الذي يمكن عن طريقه الوصول إلى
القيمة.
Value2 : القيمة المُُربِتِطة بالمفتاح الثاني في القاموس.
ملاحظة:إن قيمة المفتاح هي قيمة لا يمكن تكرارها،أي لا يمكن أن يحتوي القاموس على مفتاحين يحملان نفس الاسم.
مثال:
دعنا الآن نقوم بإنشاء قاموس خاص بمجموعة من كلمات اللغة الإنجليزية ومعانيها
باللغة العربية، ثمََّ طباعتها من خلال البرنامج التالي:
عند ادخال البرنامج (IDLE) وتنفيذه تظهر النتائج التالية:
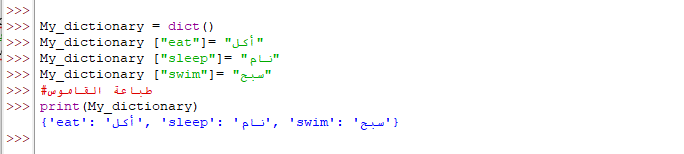
لاحظ أن البرنامج قام بعرض محتويات القاموس من خلال إستخدام أقواس المجموعة {} وأن الكلمة التي تمثل المفتاح تم طباعتها بين إشارات الاقتباس ومن ثم تليها نقطتين رأسيتين ومن ثم الكلمة التي تمثل القيمة. وتم الفصل بين عناصر القاموس من خلال الفواصل العادية.
4.المجموعات (Sets)
يمكن تعريف المجموعات على انها إحدى هياكل البيانات المركبة في لغة البرمجة بايثون والتي تحتوي على مجموعة من العناصر. وتمتاز المجموعات بانها:
- تعمل على تخزين عناصر غير متكررة (لا يُسمح بتكرار العنصر داخل المجموعة)
- لا يُشترط الترتيب للعناصر
- لا يوجد فهرسة للعناصر ،أي لا يمكن الوصول الى العنصر من خلال الموقع (Index)
- يمكن التعديل على المجموعة من حيث الإضافة والحذف.
- تدعم العمليات الحسابية حيث يمكن استخدامها لغايات عمليات التقاطع،الاتحاد والفرق بين المجموعات.
- السرعة في الأداء،إذ تعتبر أسرع من القوائم أثناء عمليات البحث والمقارنة وذلك بسبب عدم وجود ترتيب للعناصر داخلها.
مثال:
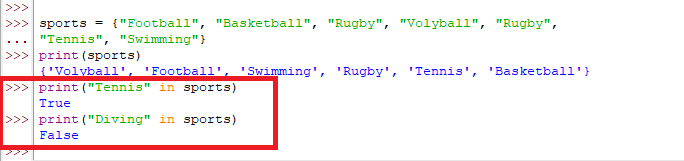
لنكتب برنامجًا يقوم بإنشاء مجموعة تمثل أنواع مختلفة من الرياضة (ولنقم بتكرار نوع اكثر من مرة)التي ممكن ممارستها ومن ثم طباعة المجموعة .
الحل:
نكتب البرنامج التالي من خلال محرر بايثون:

وبعد تنفيذ البرنامج تظهر لدينا النتيجة التالية:

لاحظ ان البرنامج قام بحذف العناصر المتكررة، وهذا لأن المجموعة لا تسمح بالتكرار.
والآن ،لنطلب من البرنامج إختبار فيما اذا كانت رياضة (Tennis) ورياضة (Diving) موجودات داخل المجموعة أم لا ؟
سوف تظهر لنا النتائج كما في الشكل التالي:
5.نوع البيانات المجردة (Abstract Data Type: ADT)
الى الآن تعرفنا على أربعة أنواع من هياكل البيانات المركبة والتي يتم استخدامها في برمجية بايثون، ولا بدّ انك لاحظت ان جميع هذه الانواع كانت تستخدم لغايات تخزين البيانات اعتمادًا على نوع البيانات والغرض من استخدامها.
وتعرفنا أيضا الى ان طريقة تخزين البيانات تعتمد على عوامل هي:
- إمكانية التعديل على البيانات من عدمه
- إمكانية تكرار العناصر في هياكل البيانات من عدمه
- طبيعة العمليات المراد تنفيذها على العناصر.
حيث أن كل نوع من تراكيب البيانات التي تعرفنا عليها سابقا (القوائم،الصفوف،القواميس،المجموعات) كانت تمتاز بخصائص محددة تُناسب متطلبات ومهمات محددة.
وهنا سوف نتعرف على تركيب محتلف عن تراكيب البيانات السابقة والذي يهتم ويركز على السلوكات أو العمليات(مثل القراءة والتعديل) أو العمليات الحسابية.
وهذا النوع من تراكيب البيانات المركبة يُطلق عليه اسم "نوع البيانات المجردة" (Abstract Data Type: ADT)
ومن أشهر الامثلة على نوع البيانات المجردة (Abstract Data Type: ADT):
- القوائم المرتبطة (Linked List)
- المكدسات (Stacks)
أوََّلاًً- القوائم المُُترابِِطة (Linked List):
يتكون هذا النوع من هياكل البيانات من عدد من العناصر المرتبطة ببعضها البعض، حيث يتكون كل عنصر من قيمة ورابط (مؤشر) إلى العنصر التالي في القائمة.
ويتم تخزين البيانات في القوائم المترابطة على هيئة عُقد(Node) ،وكل عقدة تحتوي على مرجعية العقدة التي تليها.
والشكل التالي يمثل الآلية العامة التي يتم فيها التعامل مع البيانات في القائمة المرتبطة:
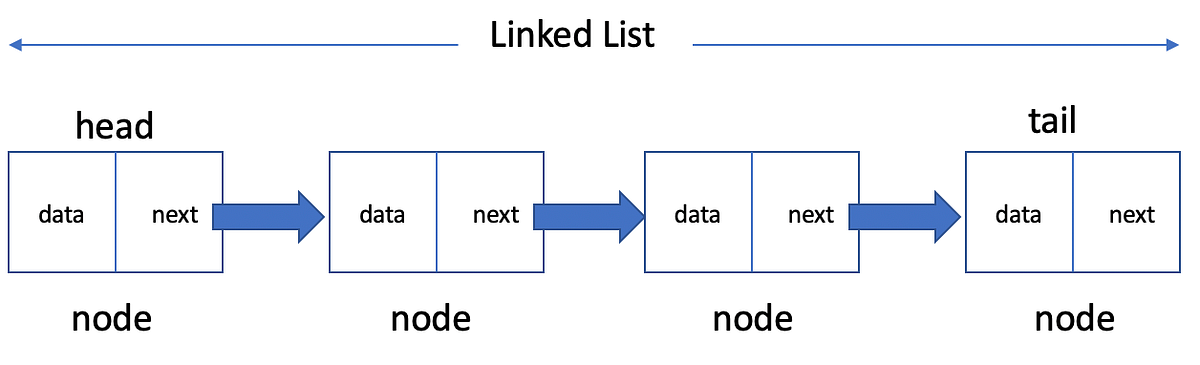
حيث (node) او ما يسمى بالعقدة يتكون من جزأين: جزء الـ(Data) والتي تحتوي قيمة وجزء (next) والذي يمثل مرجعية العقدة التالية.
ويطلق على اول عقدة في القائمة المرتبطة (Head) ويطلق على آخر عقدة في القائمة المرتبطة (Tail)
يتم استخدام القائمة المرتبطة عادة لحفظ وإدارة مجموعات من البيانات التي تحتاج إلى تحديد العلاقات بينها، مثل قائمة الايميلات أو الكتب في مكتبة وتشتهر القوائم المرتبطة بامكانيتها وقدرتها التي تكون اكبر من قدرة ال Arrays في حذف وإدراج البيانات بكفاءة في وسطها .
إنّ أشهر التطبيقات التي يُستخدم فيها القوائم المترابطة :-
- التطبيقات التي تتغير فيها حجوم البيانات
- عمليات التخزين المؤقت
- تتبع العمليات الخاصة بأنظمة التشغيل.
- تتبع الصفحات المحررة
- إضافة الرسوم التي تُستخدم في تمثيل الأشكال الهندسية
ثانيًا:المكدس (The Stack ADT)
المكدس (Stack) هو هيكل بيانات يمثل نوع من انواع البيانات المجردة(ADT) يُستخدم لتخزين البيانات بطريقة LIFO (Last In, First Out)، بمعنى أن العنصر الذي يتم إضافته أخيرًا إلى المكدس هو الذي يتم إزالته أولاً.
أي انّ هذا النوع من هياكل البيانات له بوابة واحدة فقط يتم استخدامها كمدخل ومخرج للبيانات،وعادة يكون هو الجزء العلوي من المكدس(Stack).
والشكل التالي يمثل بنية المكدس(Stack):

وفيما يلي شرحًا حول أكثر العمليات المتداولة على المكدسمن خلال الدول والأوامر التالية:
push : يتم من خلال هذه العملية إضافة عنصر جديد الى المكدس (stack)، وتتم عملية الإضافة في نهاية القائمة (من الأعلى) التي يحتويها المكدس(stack).
وتتم هذه العملية في لغة بايثون من خلال كتابة الاوامر التالية:
stack = [ ]
stack.push( )
print(stack)
pop : يتم من خلال هذه العملية حذف العنصر الذي دخل أخيرا إلى المكدس (stack) . وتتم هذه العملية في لغة بايثون من خلال كتابة الاوامر التالية:
stack.pop()
print(stack)
peek or top :يتم من خلال هذه العملية إرجاع العنصر الموجود في أعلى المكدس (آخر عنصر مضاف ) دون إزالته من المكدس (stack).
وتتم هذه العملية في لغة بايثون من خلال كتابة الاوامر التالية:
top_element=stack [ ]
print(top_element)
size: يتم من خلال هذه العملية معرفة العدد الكلي للعناصر التي تتواجد في لحظة تنفيذ الأمر داخل المكدس (stack).
وتتم هذه العملية في لغة بايثون من خلال كتابة الاوامر التالية:
size=len(stack)
print(size)
مثال:
# Example of a stack implemented as a list
stack = [10, 20, 30, 40]
# Get the size of the stack
size = len(stack)print(f"The size of the stack is: {size}")
النتيجة :
The size of the stack is: 4
Is_empty : يتم استخدام هذا الامر لمعرفة فيما إذا كان المكدس (stack) فارغًا أم لا. حيث يتم التعامل مع المكدس (stack) على أساس أنه قيمة صحيحة أو خاطئة.
فإذا كان المكدس (stack) فارغا فسوف تكون النتيجة خطأ، ولكن لأن العيارة مسبوقة ب (not) سوف يتم عكس النتيجة وتصبح صح (True) .
واذا كان فإذا كان المكدس (stack) يحتوي على عناصر فسوف تكون النتيجة صح، ولكن لأن العبارة مسبوقة ب (not) سوف يتم عكس النتيجة وتصبح خطأ (False) .
وتتم هذه العملية في لغة بايثون من خلال كتابة الاوامر التالية:
stack = []
التحقق باستخدام الشرط #
is_empty = not stack
print ("Is the stack empty?", is_empty)