
مقدمة
تعلمنا في الدرس السابق الى أدوات تحليل البيانات، ومن الادوات التي استعرضناها :
1.لغة البرمجة بايثون (Python)
2.برمجية اكسل (Excel)
حيث تعرفنا الى انّ لغة البرمجة بايثون تستخدم في تحليل البيانات وذلك لانها تتمتع بعدد من المميزات والتي من أبرزها احتواؤها على مجتمع عالمي ضخم،حيث تحتوي على اكثر من (137000) مكتبة متخصصة في عدد من المجالات المختلفة.
وسوف نقوم سويا من خلال هذا الدرس بالتعرف على كيفية تثبيت هذه المكتبات الخارجية وإستخدامها في جمع البيانات واستكشافها وتحليلها من خلال الادوات المناسبة.
جمع البيانات وتحليلها:
تعرفنا في الدرس السابق الى عدد من طرق جمع البيانات والتي كانت تشمل كل من:
1.المقابلات
2.الاستبانات
3.المسوحات او الإستطلاعات
4.الملاحظة
5.مجموعات التركيز
6.دراسة الحال.
وتعلمنا أيضا أنه يمكن تفريغ هذه البيانات وتنظيمها وتحليلها من خلال أداوات متعددة من أشهرها برمجية إكسل وبرمجية بايثون.
ومن أشهر المكتبات الخارجية التي توفرها برمجية بايثون و التي تستخدم في تحليل البيانات وعرضها:
مكتبة (Pandas)
مكتبة (NumPy)
مكتبة (Matplotlib)
و لنتذكر بأنّ هذه المكتبات ليست مثبة بشكل افتراضي مع الحزمة الاساسية التي يتم تحميلها أثناء تحميل برمجية بايثون. لذا يجب تثبيتها بشكل منفصل.
تثبيت المكتبات الخارجية في برمجية بايثون:
كما تعلمنا سابقًا،يمكننا تثبيت ما نحتاج من خلال شاشة الاوامر Command Prompt والتي يمكن الوصول لها من خلال نظام التشغيل المثبت على الجهاز بعد كتابة الامر cmd كما يظهر معنا في الشكل التالي:
مثال:
والآن دعنا نقوم بتحميل المكتبة التي تحمل الإسم (Pandas)
الحل:
نذهب الى شاشة الأوامر (Command Prompt ) من خلال الأمر cmd
فتظهر لنا الشاشة التالية:
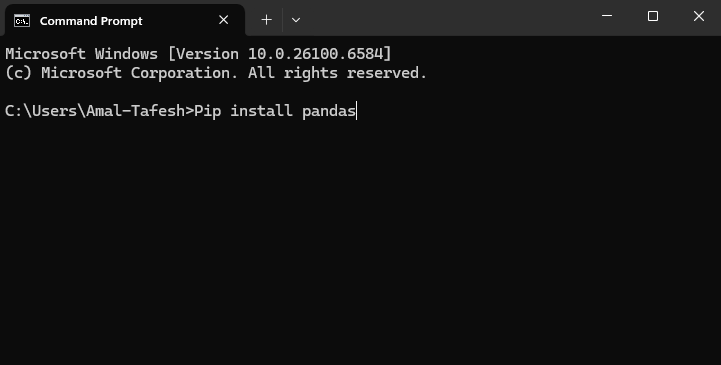
نقوم بكتابة الأمر الآتي:
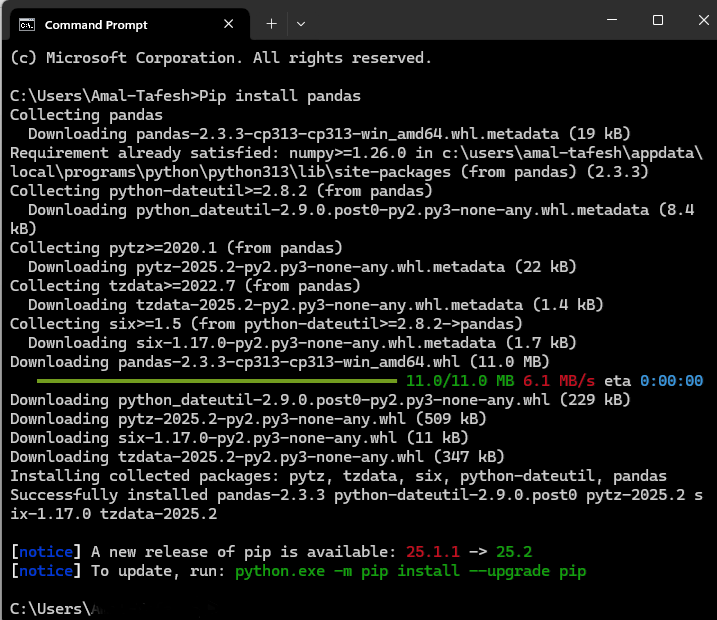
C:\>Pip install pandas
كما يظهر معنا في الشكل التالي:
وبعد الضغط على مفتاح الدخول Enter، تبدأ عملية تحميل الملفات الخاصة بالمكتبة (Pandas) كما يظهر معنا في الشكل التالي: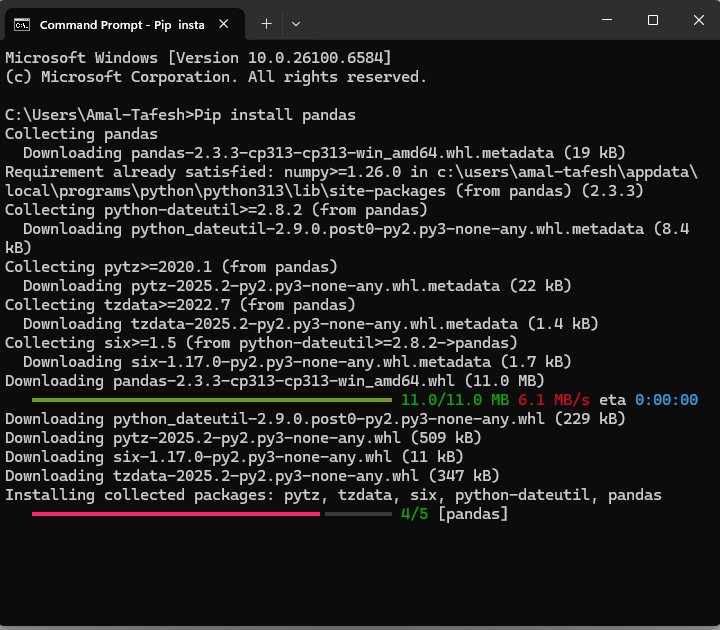
وعند الإنتهاء من عملية التحميل تظهر لنا الشاشة التالية:
استدعاء ملف بيانات في برمجية بايثون:
حتى تستطيع لغة البرمجة بايثون القيام بتحليل ملف بيانات معين، لا بدّ من إستدعاء هذه البيانات إلى مفسر لغة البرمجة بايثون. وحتى تتم هذه العملية، لا بدّ من إستدعاء المكتبات اللازمة لمعالجة البيانات وتحليلها.
وفيما يلي خطوات استدعاء ملف بيانات في برمجية بايثون:
1.استدعاء مكتبة من المكتبات التي تساعد في تحليل الملف. وهنا سوف نستدعي مكتبة (pandas)
من خلال الامر: Import pandas
2.قراءة الملف من خلال الدالة : read_csv من داخل مكتبة (pandas) وذلك من خلال الأمر:
df=pandas.read_csv(“C:\\ Users\\user\\OneDrive\\Desktop\\apple_products.csv")
حيث:
df: تمثل اسم المتغير الذي سوف تُخزن فيه البيانات التي تم استدعاؤها.
pandas.read_csv: الدالة التي سوف تقوم بقراءة الملف الذي امتداده من نوع (csv)
products.csv apple_: اسم الملف الذي سوف يتم استدعاؤه
C:\\ Users\\user\\OneDrive\\Desktop\\apple_products.csv: المسار الكامل للملف (أي الموقع الذي تم تخزين الملف فيه على جهاز الكمبيوتر)
ملاحظة:
- يجب كتابة المسار داخل قوسين مزدوجين " "
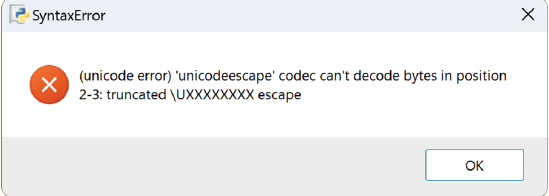
- يجب استخدام رمز (Backslash) بشكل مزدوج \\
- .في حال تم استخدام إشارة (\) واحدة، وبعد تنفيذ البرنامج، سوف تظهر لنا إشارة تخبرنا بوجود خطأ كما في الشكل التالي:
- لغايات معرفة مسار أي ملف،نقوم باختيار الملف المطلوب،ثم الضغط على الزر الأيمن للفأرة،حيث تظهر القائمة المنسدلة التي في الشكل التالي:
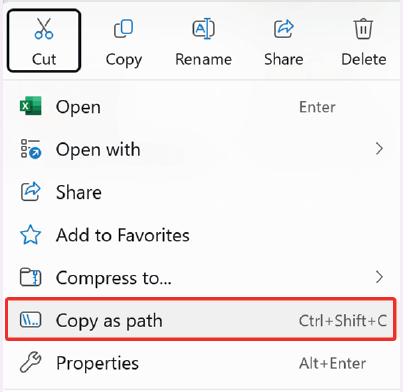
- وبعدها نقوم باختيار الخيار (Copy as Path) المظلل بالمستطيل الاحمر
3.طباعة البيانات :كما تعلمنا سابقًا ،فإنّ طباعة البيانات وظهررها على شاشة المخرجات يتم من خلال الأمر (Print ).
وحتى نستطيع استدعاء ملف بيانات وطباعته نقوم بكتابة المقطع البرمجي التالي:
Import pandas
(“C:\\ Users\\user\\OneDrive\\Desktop\\apple_products.csv")df=pandas.read_csv
print (df)
ولنتذكر هنا: إنّ الملف المراد قراءة بياناته،يجب أن يكون من إمتداد (CSV)
وبعد تنفيذ هذا المقطع البرمجي، تظهر لنا النتيجة كما في الشكل التالي:

نلاحظ من المخرجات ما يلي:
تقوم البرمجية بعرض أول خمسة أسطر وآخر خمسة أسطر فقط من الملف.
تقوم البرمجية بطباعة أول عمودين وآخر عمودين إذا كان عدد الأعمدة كثيراً
تقوم البرمجية بطباعة إجمالي عدد الصفوف والأعمدة في الجدول الأصلي.
عرض ملف البيانات كاملًا:
يُمكن عرض جميع الأسطر والأعمدة للبيانات وذلك من خلال تغيير الإعدادات الإفتراضية
بإستخدام الدالة set_ option
والتي يمكن توظيفها من خلال كتابة المقطع البرمجي التالي :
وبعد تنفيذ المقطع البرمجي أعلاه، تظهر لنا نتيجة عرض الملف الذي يحمل الإسم (testdoc.csv) بجميع سطوره وأعمدته على الشكل التالي:


تحليل الإحصاءات الوصفية Descriptive Statistics في برمجية بايثون:
تحليل الإحصاءات الوصفية ) Descriptive Statistics ( في برمجية بايثون:
إن مصطلح الإحصاء الوصفي هو فرع من علم الإحصاء، حيث يعتبر خطوة أساسية في أي تحليل أي بيانات لغايات فهم طبيعة البيانات المتاحة قبل الانتقال إلى التحليلات الأكثر تعقيدًا.و يهدف إلى:
- جمع البيانات وتلخيصها وتنظيمها
- تقديم البيانات على شكل سهل الفهم باستخدام جداول ورسوم بيانية
- تقديم البيانات على شكل مقاييس عددية مثل المتوسط والوسيط والمنوال والانحراف المعياري لفهم خصائص مجموعة البيانات دون عمل استنتاجات أوسع.
تستخدم برمجية بايثون ثلاث فئات رئيسة من الإحصاءات الوصفية هي:
1.مقاييس النزعة المركزية: تُستخدم لوصف نقطة التجمع أو المركز في مجموعة بيانات، وتساعد في تلخيص المعلومات وتقديم صورة موجزة عنها. تشمل المقاييس الثلاثة الأكثر شيوعًا المتوسط الحسابي، والوسيط، والمنوال. يُمثل المتوسط الحسابي مجموع القيم مقسومًا على عددها، بينما الوسيط هو القيمة الوسطية بعد ترتيب البيانات، ويُعد المنوال القيمة الأكثر تكرارًا في البيانات.
2.مقاييس التشتت: هي مقاييس عددية تقيس درجة انتشار البيانات وتباعدها عن بعضها البعض أو عن نقطة مركزية كالمتوسط. تُستخدم هذه المقاييس لوصف توزيع البيانات، وتقييم مدى تجانسها، ومقارنة مجموعات بيانات مختلفة. من أشهر أنواع مقاييس التشتت: المدى، الانحراف المتوسط، التباين، الانحراف المعياري، و معامل الاختلاف.
3.التكرارات: يُقصد بهاعدد مرات ظهور قيمة معينة أو وقوع حدث معين في مجموعة بيانات مما يساعد على تحديد أكثر القيم شيوعًا،حيث . تُستخدم التكرارات لتنظيم البيانات وتصويرها في جداول التوزيع التكراري، التي توضح عدد الملاحظات أو القيم التي تندرج ضمن كل فئة أو قيمة محددة، مما يسهل فهم توزيع البيانات وتحديد أنماطها.
ويمكن الحصول على بيانات الاحصاءات الوصفية لأي ملف في برمجية بايثون من خلال الدالة :describe()
إذ يمكننا استخدا الأمر:
Print (df.describe() )
لغايات تعريض بيانات ملف للتحليل الإحصائي الوصفي وذلك ما يظهر المقطع البرمجي التالي:
Import pandas
(“C:\\ Users\\user\\OneDrive\\Desktop\\apple_products.csv" )df=pandas.read_csv
Print (df.describe() )
حيث :
df: اسم النتغير الذي خُزنت فيه البيانات
describe(): الدالة التي تعمل على حساب الإحصاءات الوصفية للبيانات
apple_products: اسم الملف الذي سوف يخضع للتحليل الإحصائي الوصفي.
وبعد الانتهاء من تنفيذ المقطع البرمجي الذي في الأعلى، تظهر لنا الإحصاءات الوصفية للبيانات كما في الشكل التالي:
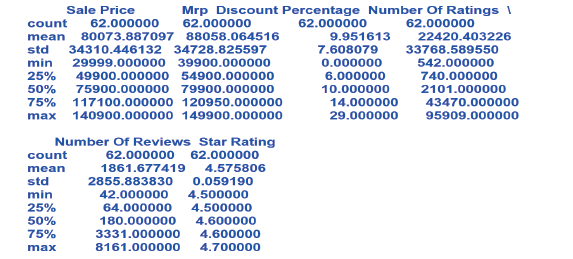
والذي يحتوي على الأعمدة الرقمية التالية:
Sale Price Star Rating Number Of Review Number Of Ratings Mrp Discount Percentage
ويمكن من خلاله قراءة المعلومات التالية:
- الصف الأوَّل يُظهِر التكرار Count الذي يُمثِّل عدد القِيَم غير المفقودة في كل عمود. فمثلًًا، جميع الأعمدة تحتوي على 62 قيمة، في ما يُمثِّل عدد الأسطر نفسها.
- الصف الثاني يُظهِر الوسط الحسابي ( Mean ) لكل عمود. فمثلًًا، الوسط الحسابي لعمود
Sale Price هو80073.887097
133
- الصف الثالث يُظهِر الانحراف المعياري ( Standard Deviation: std )الذي يقيس مدى تشتُّت القِيَم حول الوسط الحسابي. فمثلًًا، الانحراف المعياري لعمودReviews Number Of هو 2855.883830
- الصف الرابع يُظهِر القيمة الصغرى min وهي أقلُّ قيمة لكل عمود. فمثلًًا، أقلُّ قيمة لعمود Star Rating هي 4.500000.
- الصف الخامس يُظهِر المئين25 (25) ويُمثِّل الربيع الأوَّل، وهو القيمة التي تفصل أوَّل 25 %من البيانات عن البقيَّة.
- الصف السادس يُظهِرالمئين 50 (50%)، ويُعرَف بالربيع الثاني أو الوسيط، وهوالقيمة الوسطى للبيانات.
- الصف السابع يُظهِر المئين 75(75%)، ويُمثِّل الربيع الثالث، وهو القيمة التي تفصل 75 % من البيانات عن أعلى 25%.
- الصف الثامن يُظهِر القيمة العظمى (max)، وهو أكبر قيمة لكل عمود.
عرض البيانات باستخدام برمجية بايثون:
يمكننا عرض البيانات من خلال برمجية بايثون على شكل مخططات بيانية متنوعة مثل (مخططات خطية، مخططات على شكل أعمدة،مخططات تشتت ومخططات على شكل دائري) .
حيث إنّ عرض البيانات على شكل رسوم بيانية يساعد على فهم البيانات وإمكانية قراءتها بصورة واضحة.
ومن أشهر المكتبات الخارجية التي تستخدمها بايثون لعرض البيانات مكتبة (Matplotlib) والتي تحتوي على دوال عدة تمكنها من تنسيق المخططات البيانية وإنشائها.
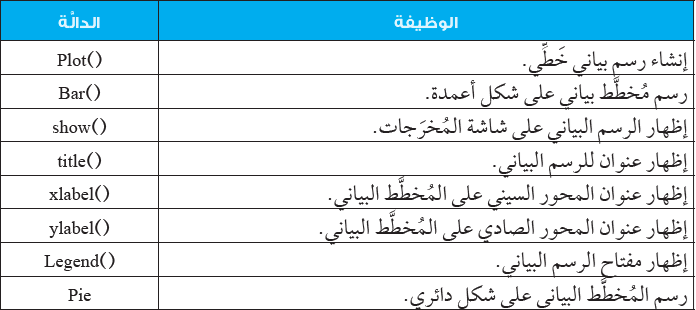
ويظهر الجدول التالي عددًا من الأمثلة على الدوال الشائعة في مكتبة (Matplotlib):
وسوف نتعرف سويًا على آلية عرض البيانات ضمن الأشكال التالية:
عرض البيانات برسم بياني خََطِِّي( Line Chart )
حتى نستطيع رسم مخطط بياني يعرض إسم الطالب ومعدله من خلال برمجية بايثون، يجب القيام بالخطوات التالية:
1.إستدعاء المكتبات الخارجية
كما تعلمنا،يتم إستخدام الامر (import) لغايات إستدعاء المكتبات الخارجية. وهنا نحتاج الى إستدعاء مكتبة (Pandas) المسؤولة عن تحليل البيانات ومكتبة (Matplotlib) المسؤولة عن عرض البيانات والتي تحتوي على الوحدة الفرعية التي تسمى (pyplot) والتي تساعد على رسم المخططات البيانية.
ويمكن ترجمة ما سبق من خلال كتابة الاوامر التالية:
Import pandas
Import matplotlib.pyplot as plt
2.إضافة عنوان الى المخطط البياني
المقصود هنا، أننا نستطيع تسمية هذا الرسم البياني من خلال أضافة عنوان والذي يتم من خلال الدالة title من مكتبة (Matplotlib).
ويمكن ترجمة ما سبق من خلال كتابة الامر التالي:
plt.title(‘average of Class’)
3.إضافة عناوين إالى المحاور في المخطط البياني
يمكن إضافة عنوان للمحور السيني (X-axis) وإضافة عنوان للمحور الصادي (Y-axis) من خلال الأمر البرمجي التالي:
plt.xlabel(‘Name’)
plt.ylabel(‘Average’)
4.رسم المخطط البياني الخطي
ولغاية رسم المخطط البياني يتم إستخدام الدالة plot وذلك من خلال الامر:
plt.plot(data[‘name’],data[‘average’])
حيث:
تأخذ الدالةََ plot مُُعامِِلين أساسيين، هما:
المُُعامِِل X-axis يُُمثِِّل هذا المُُعامِِل القِِيََم على المحور الأفقي )السيني(. وفي هذا المثال،
فإنََّه يُُعََدُُّ المُُتغيِِّر في عمود name
المُُعامِِل Y-axis يُُمثِِّل هذا المُُعامِِل القِِيََم على المحور العمودي )الصادي(. وفي هذا المثال،
فإنََّه يُُعََدُُّ المُُتغيِِّر في average
تَكَتب أسماء الأعمدة )المُُتغيِِّرات( التي سيتمُُّ رسمها باستخدام الدالََّة plot ، وذلك بوضع اسم
العمود بين قوسين مُُربََّعين [ ] بعد اسم المُُتغيِِّر الذي يحتوي على البيانات، وهو في هذا المثال
(data)
5.إظهار الرسم البياني على شاشة المخرجات
ويتم هذا الأمر من خلال الدالة show() من الوحدة الفرعية من المكتبة التي تعاملنا معها (matplotlib.pyplot).
وذلك من خلال كتابة الأمر البرمجي التالي:
plt.show()
واعتمادا على ما سبق،يمكن لنا كتابة المقطع البرمجي التالي:
والذي بعد تنفيذه يظهر لنا الرسم البياني الخطي كما في الشكل التالي:
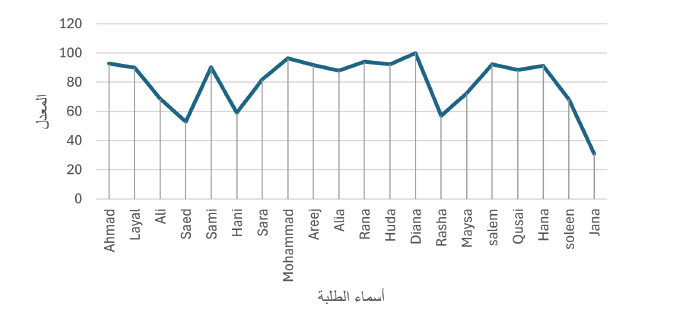
والآن، إعتمادًا على هذا الرسم، هل نستطيع الإجابة على الأسئلة التالية:
من صاحب أدني معدل؟
من صاحب أعلى معدل؟
هل يمكن مقارنة علامات الطالبة Areej مع الطالبة Rana ومعرفة من الاعلى؟
عرض البيانات على هيئة رسم بياني بالأعمدة ( Bar Chart (
أكثر ما نحتاج الرسم البياني بالأعمدة (Bar Chart) في الحالات التي تتطلب المقارنة بين القيم الواقعة ضمن فئات أو مجموعات. حيث يمكن إعادة الرسم البياني الخطي الذي تم شرحه بالأعلى من خلال تمثيله بواسطة (Bar Chart) وذلك من خلال إستخدام الدالة (bar) بدلًا من الدالة (plot).
بحيث يصبح المقطع البرمجي على النحو التالي:
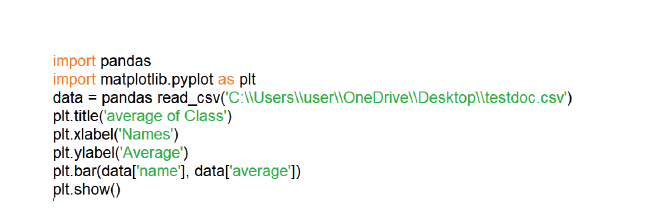
والذي بعد تنفيذه يظهر لدينا الرسم البياني التالي:
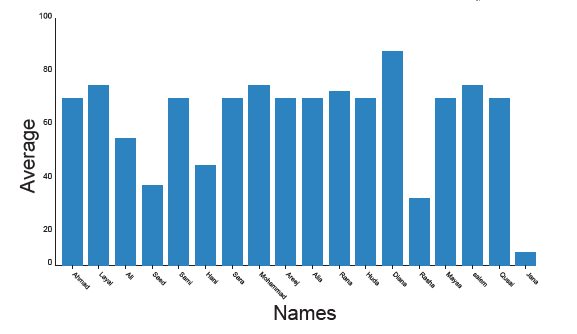
ويمكن إجراء بعض التعديلات عليه، مثل تغيير لون الأعمدة (لأن اللون الإفتراضي هو الأزرق)، كما يمكن تغيير عرض الأعمدة (إذ أنّ العرض الإفتراضي للعمود هو 0.8)
ويتم الأمر من خلال الامر البرمجي التالي:
plt.bar(data[‘name’],data[‘average’],color=’red’,width =0.5)
بدلًا من الأمر البرمجي:
plt.bar(data[‘name’],data[‘average’]
الذي كان في المقطع البرمجي السابق.
عرض ا لبيانات على شكل قطاع دائري Pie Chart
يتم استخدام هذا النوع من المخططات لغايات تمثيل النسب المئوية لكل متغير، إذ يظهر النسبة المئوية لكل عنصر مقارنة بالإجمالي.حيث يسهّل على المستخدم فهم مساهمة كل عنصر بالنسبة للبقية.
ويتم الامر من خلال إستخدام الدالة pie من مكتبة (Matplotlib).
إنّ خطوات عرض البيانات على هيئة قطاع دائري (Pie Chart) في برمجية بايثون تشبه تلك التي تم شرحها سابقا أثناء الحديث عن رسم البيانات على شكل مخطط خطي مع وجود بعض الإضافات.
وفيما يلي خطوات عرض البيانات على هيئة قطاع دائري (Pie Chart) في برمجية بايثون:
1.استدعاء المكتبات
نحتاج هنا إلى استدعاء مكتبتين:
- (matplotlib.pyplot) للوظائف الخاصة بالرسوم البيانية
- (numpy) لإنشاء مصفوفة تحتوي على النسب المئوية.
ويتم الامر من خلال كتابة الاوامر التالية:
Import matplotlib.pyplot as plt
Import numpy as np
2.تعريف البيانات
ويتم الأمر من خلال إضافة مصفوفة تحتوي على البيانات والتي تمثل هنا القيم المئوية لكل عنصر أو قسم من العناصر/الأقسام بالاضافة الى قائمة بأسماء العناصر أو الأقسام.
ويمكن تحقيق ذلك من خلال الاوامر البرمجية التالية:
y=np.array([35,25,25,15])
mylabels = [“Apples”,”Bananas”,”Cherries”,”Dates”]
3.إنشاء القطاع الدائري.
يُمكِن إنشاء القطاع الدائري باستخدام القِيَم الموجودة في y والأسماء الموجودة في( mylabels )
plt.pie(y,labels =mylabels)
4.عرض القطاع الدائري وإظهاره على الشاشة في برمجية بايثون.
plt.show()
تحديد الأنماط في الرسوم البيانية:
يقصد بتحديد الأنماط عملية التعرف عاى سلوك البيانات والإنتظامات المتكررة فيها والتي تمكننا من إتخاذ القرارات المناسبة بناءًا على هذه السلوكات.و يستفاد منهافي علم تعلم الآلة، حيث تقوم الأنظمة بتحليل البيانات الرقمية والصور والأصوات لتحديد الأنماط مثل التعرف على الوجوه في الصور أو الأصوات في الكلام. كما يُستخدم في التحليل المالي والتسويق لاستنتاج الأنماط في بيانات العملاء.
ويمكن قراءة هذه السلوكات والتعرف على الأنماط من خلال الرسوم البيانية ،مما يساعد في اتخاذ القرارات .
وكي نفهم أكثر،لنقم بدراسة هذا المثال:
والذي يُُمثِِّل الرسم البياني الخََطِِّي الذي أُُنشِِئ باستخدام برمجية بايثون لتمثيل
بيانات عن مجموع محصول التفّّاح والبرتقال في بلدة ( Kanto ) خلال الأعوام (2000 - 2010 م)
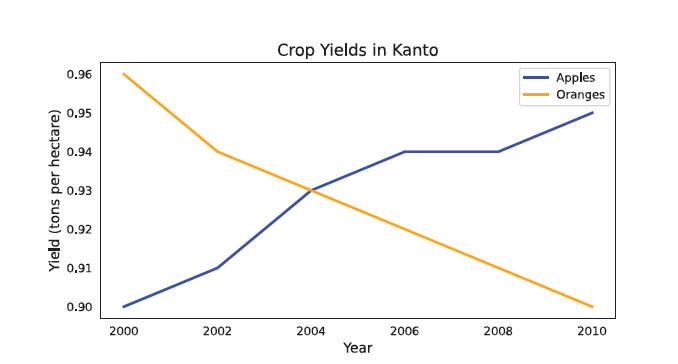
نلاحظ أنََّ الخََطََّ الأزرق يُُمثِِّل مجموع إنتاج التفّّاح في البلدة على مدار تلك الأعوام، وأنََّ اتِِّجاه البيانات موجب؛ ما يعني أنََّ إنتاج التفّّاح قد شهد زيادة تدريجية أثناء تلك الأعوام.
ونلاحظ الخََطُُّ البرتقالي يُُمثِِّل مجموع إنتاج البرتقال خلال المُُدََّة الزمنية نفسها. إلا
أنََّ اتِِّجاه البيانات سالب؛ مما يعني أنََّ إنتاج البرتقال انخفض تدريجيًًّا بمرور الوقت.
وإعتمادًا على هذا السلوك والانماط الذي أظهرها الرسم البياني، ممكن أن نستنتج:
أن هناك تغيُُّرات واضحة في إنتاج المحاصيل ببلدة (Kanto ) ؛ إذ شهد إنتاج التفّّاح زيادة مستمرة، في حين انخفض إنتاج البرتقال بصورة تدريجية.
وعليه يمكن البحث في الأسباب التي أفضت إلى تلك النتائج بهدف اتِِّخاذ قرارات مناسبة.